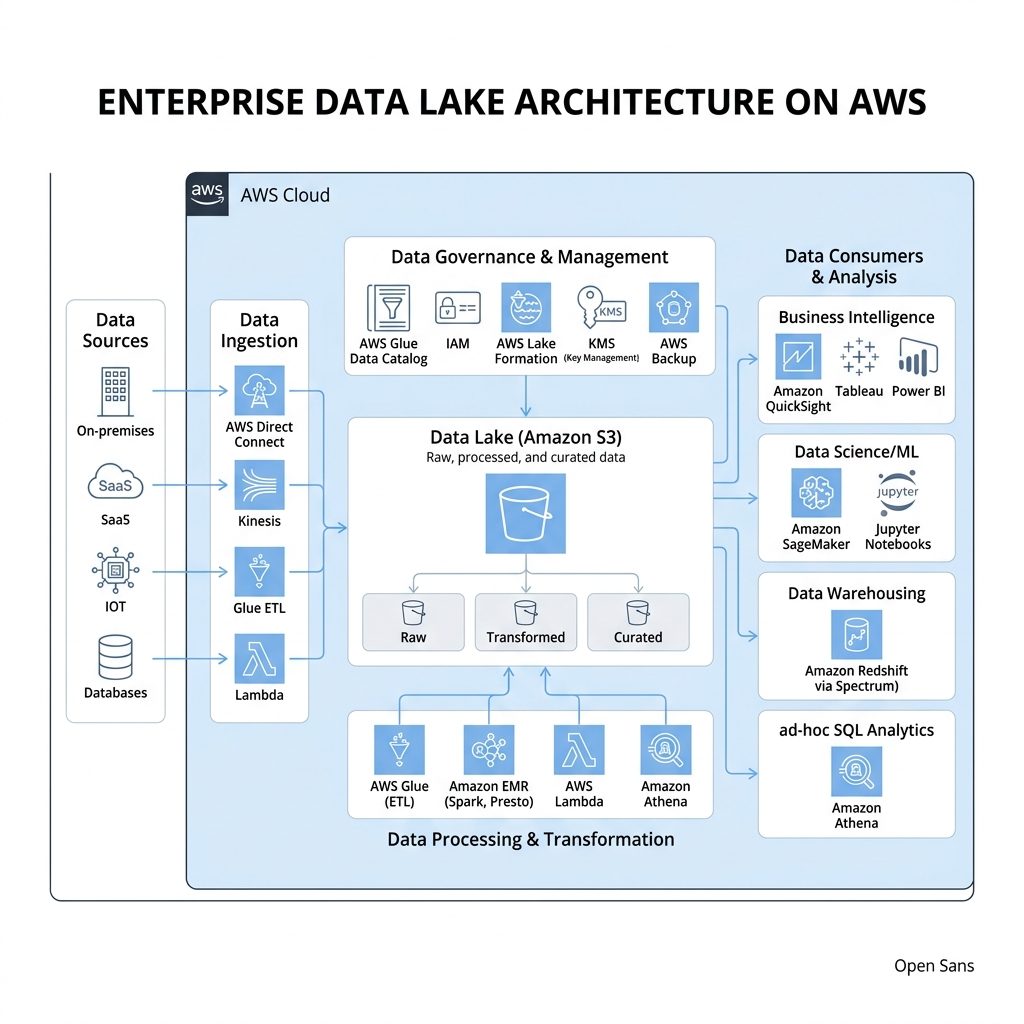
The Challenge
A media conglomerate had petabytes of unstructured clickstream and log data residing in disparate silos. Data scientists were spending 70% of their time on data preparation rather than analysis, and the costs of storing this data in traditional databases were spiraling out of control.
They needed a centralized, cost-effective way to store, discover, and query this 'dark data' without the overhead of a formal warehouse for every specific use case. Data accessibility was limited to a few 'gatekeepers', creating a massive bottleneck for innovation.